Uploading a File to S3 Using Boto3 Aws Lambda
![AWS Lambda & S3| Automate CSV File Processing From S3 Bucket And Push In DynamoDB Using Lambda [Python]](https://dheeraj3choudhary.com/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1643558332957%2F5t_OfXAXf.png%3Fw%3D1600%26h%3D840%26fit%3Dcrop%26crop%3Dentropy%26auto%3Dcompress%2Cformat%26format%3Dwebp&w=3840&q=75)
AWS Lambda & S3| Automate CSV File Processing From S3 Saucepan And Push In DynamoDB Using Lambda [Python]
In this blog we are going to choice CSV file from S3 bucket once it is created/uploaded, process the file and push it to DynamoDB table.
Create Role For Lambda
- Create policy mentioned beneath.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Upshot": "Allow", "Activeness": [ "dynamodb:CreateTable", "s3:PutObject", "s3:GetObject", "dynamodb:PutItem", "dynamodb:UpdateItem", "dynamodb:UpdateTable" "logs:CreateLogDelivery", "logs:PutMetricFilter", "logs:CreateLogStream", "logs:GetLogRecord", "logs:DeleteLogGroup", "logs:GetLogEvents", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:CreateLogGroup", "logs:DeleteLogStream", "logs:GetLogDelivery", "logs:PutLogEvents" ], "Resource": "*" } ] } - Now create new role for lambda and attach this policy to the role.
Create S3 Bucket And Attach Tags
Creates a new S3 saucepan. To create a bucket, y'all must annals with Amazon S3 and have a valid Amazon Web Services Access Key ID to cosign requests. Anonymous requests are never allowed to create buckets. By creating the bucket, you become the bucket owner.
- Lets import boto3 module
import boto3 - We will invoke the customer for S3
client = boto3.client('s3') - Now we will use input() to take bucket proper noun to be create as user input and will store in variable "bucket_name".
Notation:- Make sure to check the bucket naming rules herebucket_name=str(input('Please input bucket proper noun to be created: ')) - Goto link where y'all volition find all arguments list. Based on your requirement you can put this arguments to list your S3 buckets. This document also mentions datatype of the parameter.
Note:-Bucket Name statement is mandatory and saucepan name should be uniqueresponse1 = client.create_bucket( ACL='public-read-write', Bucket=bucket_name ) - Now we will use input() to confirm if user wants to go alee with bucket tagging via user input and will store information technology in variable "tag_resp".
tag_resp=str(input('Press "y" if y'all want to tag your saucepan?: ')) - Now we volition use if status and accept user input for tags which needs to be divers for bucket.
We will shop tag key in variable "tag_key" and tag value in "tag_value". To add together tag to bucket nosotros are going to apply put_bucket_tagging() method, make sure to bank check official documentation hither In method parameters we are passing variable as "bucket_name","tag_key","tag_value".
To view entire github code please click hitherif tag_resp == 'y': tag_key=str(input("Delight enter key for the tag: ")) tag_value = str(input("Please enter value for the tag: ")) response2 = customer.put_bucket_tagging( Saucepan=bucket_name, Tagging={ 'TagSet': [ { 'Cardinal': tag_key, 'Value': tag_value } ] })
Create DynamoDB Table
- Python lawmaking in one module gains access to the lawmaking in another module by the procedure of importing it. The import argument combines two operations it searches for the named module, then it binds the results of that search to a name in the local scope.
import boto3 - We volition invoke the resources for DyanamoDB.
dynamodb = boto3.resource('dynamodb') - We will use create_table() part to create table in Dynamo DB with following arguments listed below. Here nosotros will run into 2 examples one with "primary keys only" and another with "master key and sort key". You tin find official documentation hither.
Example1:- Beneath code is to create tabular array with chief primal onlytabular array = dynamodb.create_table( TableName='user', KeySchema=[ { 'AttributeName': 'id', 'KeyType': 'HASH' #Division Key Only } ], AttributeDefinitions=[ { 'AttributeName': 'id', 'AttributeType': 'S' } ], ProvisionedThroughput={ 'ReadCapacityUnits': 1, 'WriteCapacityUnits': i }, )
Lambda Function To Read CSV File From S3 Bucket And Button Into DynamoDB Table
- Goto Lambda panel and click on create function
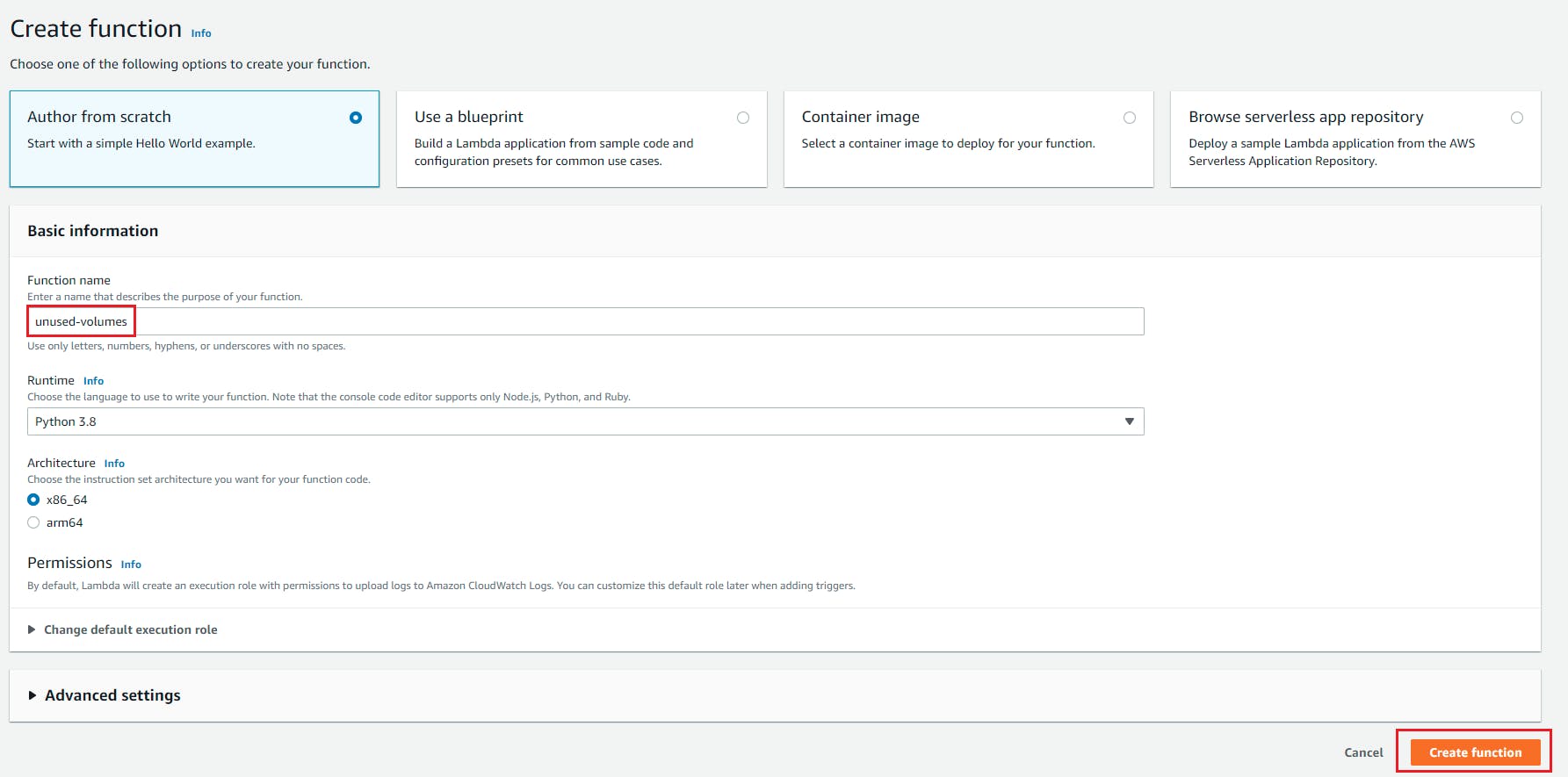
- Select "Author From Scratch" , Role proper noun = csv_s3_Lambda, Runtime= Python and role nosotros created with in a higher place policy attached to this weblog and click on create part.
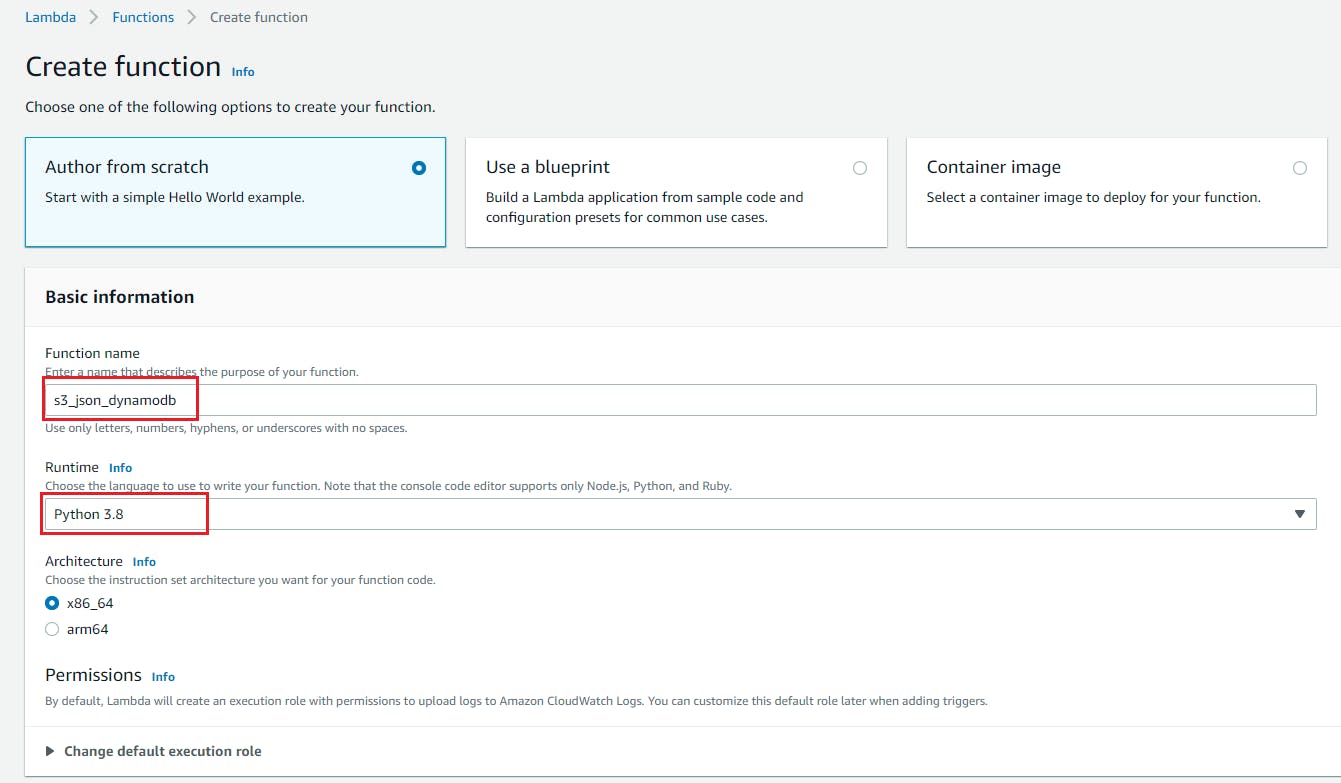
- Goto lawmaking editor and start writing the code.
- We will import 3 modules
import boto3 - We volition invoke the client for S3 and resource for dynamodb
s3_client = boto3.customer('s3') dynamodb = boto3.resource('dynamodb') - First we will fetch bucket name from outcome json object
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['proper name'] - Now we will fetch file name which is uploaded in s3 bucket from event json object
def lambda_handler(event, context): saucepan = event['Records'][0]['s3']['bucket']['name'] csv_file_name = outcome['Records'][0]['s3']['object']['cardinal'] - We will call at present get_object() function to Retrieves objects from Amazon S3. To use GET , you must accept READ admission to the object. If you lot grant READ access to the anonymous user, you tin return the object without using an authorization header. You can view this function official documentation here
def lambda_handler(event, context): bucket = result['Records'][0]['s3']['bucket']['name'] csv_file_name = event['Records'][0]['s3']['object']['key'] csv_object = s3_client.get_object(Bucket=bucket,Key=csv_file_name) - Lets decode the json object returned by function which will return string
def lambda_handler(effect, context): saucepan = result['Records'][0]['s3']['bucket']['name'] csv_file_name = event['Records'][0]['s3']['object']['fundamental'] csv_object = s3_client.get_object(Bucket=saucepan,Primal=csv_file_proper name) file_reader = csv_object['Torso'].read().decode("utf-eight") - Use Split() which will split up a string into a list where each discussion is a listing item. Brand certain to check official documentation here
def lambda_handler(issue, context): saucepan = upshot['Records'][0]['s3']['saucepan']['name'] csv_file_name = event['Records'][0]['s3']['object']['key'] csv_object = s3_client.get_object(Saucepan=bucket,Cardinal=csv_file_name) file_reader = csv_object['Torso'].read().decode("utf-8") users = file_reader.split("\n") - We will use filter() method which filters the given sequence with the help of a function that tests each element in the sequence to be true or not.. Brand sure to bank check official documentation here
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] csv_file_name = event['Records'][0]['s3']['object']['central'] csv_object = s3_client.get_object(Saucepan=bucket,Key=csv_file_name) file_reader = csv_object['Torso'].read().decode("utf-eight") users = file_reader.split up("\n") users = list(filter(None, users)) - Now we will traverse through the list option elements one by one and push button it to dynamodb table using tabular array.put_item() . Y'all tin find official documentation here.
def lambda_handler(issue, context): bucket = event['Records'][0]['s3']['saucepan']['name'] csv_file_name = outcome['Records'][0]['s3']['object']['key'] csv_object = s3_client.get_object(Saucepan=saucepan,Key=csv_file_name) file_reader = csv_object['Torso'].read().decode("utf-viii") users = file_reader.dissever("\due north") users = listing(filter(None, users)) for user in users: user_information = user.split(",") table.put_item(Particular = { "id" : user_data[0], "name" : user_data[1], "bacon" : user_data[2] }) return 'success'
Ready Outcome For S3 bucket
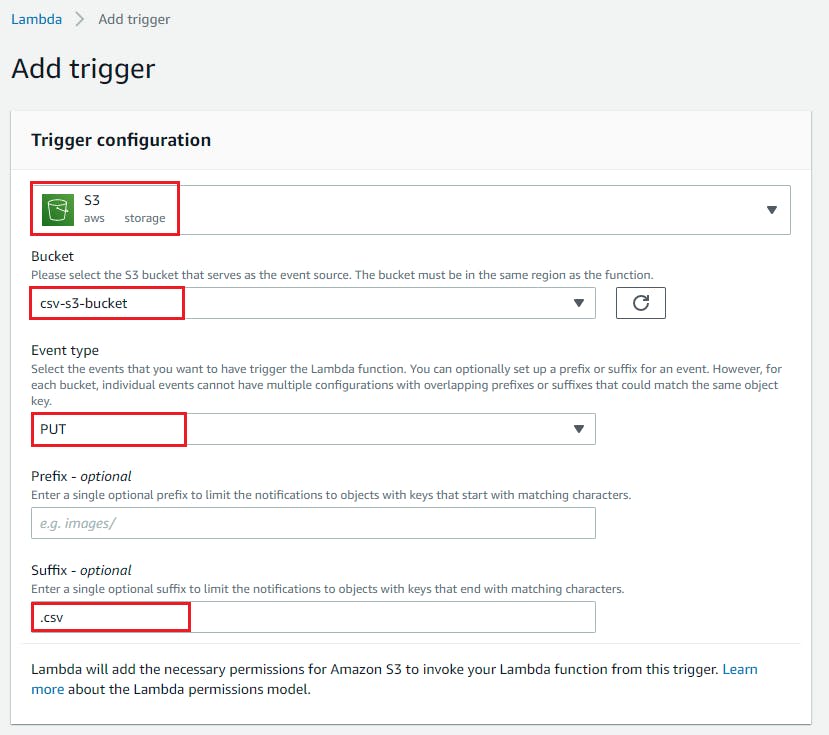
- Open up Lambda function and click on add trigger
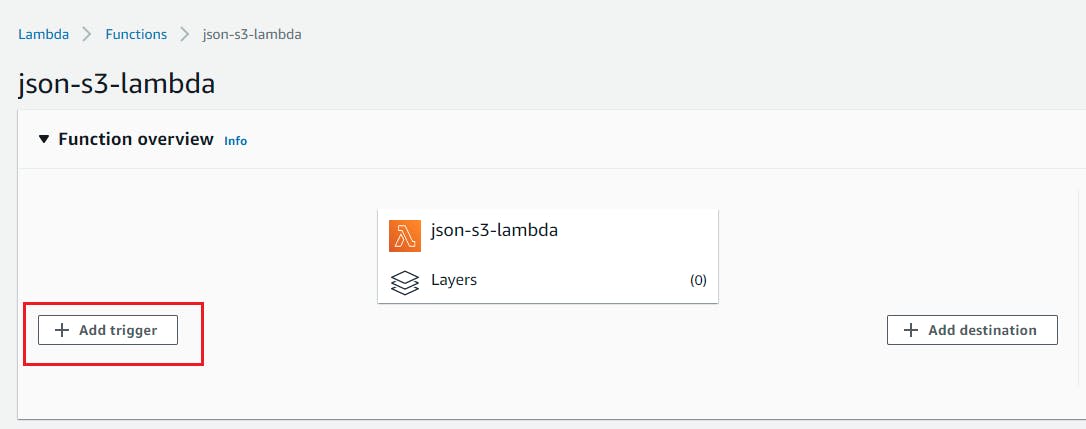
- Select S3 as trigger target and select the saucepan nosotros have created above and select event type equally "PUT" and add suffix as ".csv" Click on Add together.
Create CSV File And Upload It To S3 Bucket
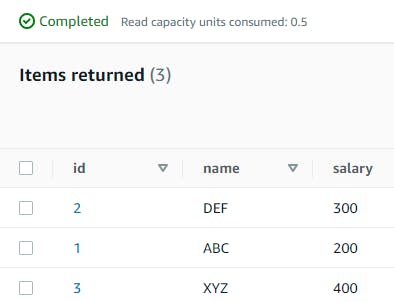
- Create .csv file with below information
1,ABC,200 2,DEF,300 3,XYZ,400 - Now upload this file to S3 bucket and it volition process the information and button this information to DynamoDB.
Youtube Tutorial
Resource Cleanup
- Delete Lambda Function
- Delete DynamoDB Table
- Delete S3 Bucket Object Commencement And so Bucket
- Delete Lambda Role
Conclusion
In this blog we are going to pick CSV file from S3 saucepan in one case information technology is created, procedure the file and push button information technology to DynamoDB tabular array.
Stay tuned for my next weblog.....
So, did you notice my content helpful? If you did or like my other content, experience free to buy me a coffee. Thanks. 
Did you find this article valuable?
Support Dheeraj Choudhary by becoming a sponsor. Any amount is appreciated!
Source: https://dheeraj3choudhary.com/aws-lambda-and-s3or-automate-csv-file-processing-from-s3-bucket-and-push-in-dynamodb-using-lambda-python